在卷积神经网络CNN中,如BN、GN等归一化层得到了普遍使用。这些层之间有什么区别、分别在什么情况下使用我一直是模棱两可,现在特意整理记录一下,搞清楚这些层的原理和区别对设计模型网络也大有裨益。
此外,本文将特意花一些篇幅探讨对各种归一化方法来说,其前边的卷积层是否需要bias,这部分内容在本文第二部分。
归一化层区分
归一化用于解决深度学习中的内部协变量移位(internal covariate shift)现象,可以用于缓解梯度爆炸、提高模型收敛速度,同时能起到正则化的作用,防止过拟合。
目前的主流归一化层有Batch Norm(BN)、Layer Norm(LN)、Instance Norm(IN)、Group Norm(GN)。其区别可以参考下图,这张图来自于论文Group Normalization[1]。
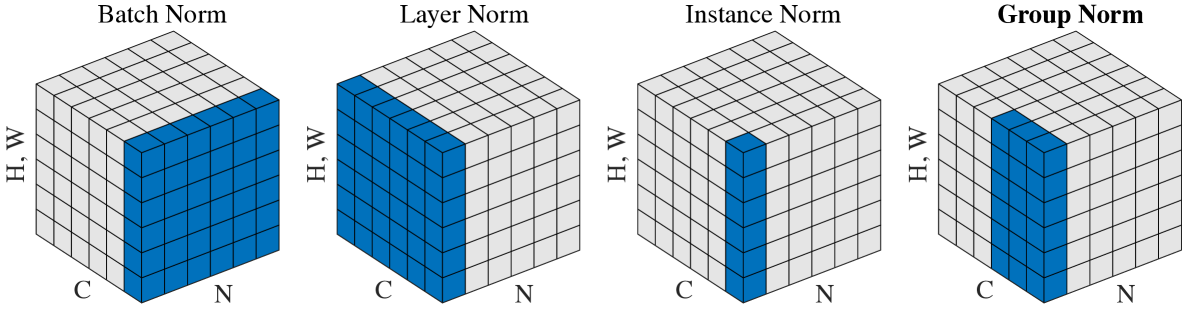
归纳起来说,无论是哪一种归一化,本质上都是将特征图分为若干个部分,分别对每个部分做归一化使其数值范围符合特定的正态分布,所以对第i个部分的归一化均可以用下式表示:
定义有一个特征图
Batch Norm(BN)[2]
BN的应用应该说是最广的,但是其对batchsize的大小很敏感,只建议在batchsize不低于8的时候使用。
BN逐通道地对整个batch的特征图做归一化,也就是说每次做归一化的特征图维度为
1 | # BN |
Layer Norm(LN)[3]
LN多用于RNN,在卷积神经网络上很少使用。
与BN相反,LN逐输入地对所有通道的特征图做归一化,每次归一化的特征图维度为
1 | # LN |
Instance Norm(IN)[4]
IN主要用于生成式模型,如基于GAN的图像生成、图像风格迁移等。
IN可以看作是BN或者LN的特例(
1 | # IN |
Group Norm(GN)
由于GN的性能不受batchsize影响,在batchsize比较小的时候,可以用GN代码BN。
GN将特征图沿通道均分为
1 | # GN |
从卷积说起——是否需要bias?
我们在设计模型结构的时候应该经常看到类似下边的代码:
1 | class BaseConv(nn.Module): |
nn.Conv2d中其他参数都很熟悉,bias=False是为什么呢?
本节将探讨这一问题,解决什么归一化不需要bias、为什么不需要的问题。
卷积实现
在pytorch中,卷积通过类
nn.Conv2d()实现,卷积层的参数有权重(weight)
定义一个卷积层,其输入通道数为
1 | conv = nn.Conv2d(C_in, C_out, kernel_size=k, stride=2, padding=1) |
那么有
也就是说,对于每个输出层来说,都有一个维度为
逐通道是不是很熟悉?没错,BN也是逐通道的,那么在使用BN的情况下,即使加了bias最后也会在减去均值的时候被去掉,因此,这时候添加bias将不会产生任何作用,反而白白占用显存和运算量。
数学推理证明
我们可以以BN为例推导一下这个过程。为简化过程,只考虑输出特征图的一个通道特征图
实际上,如果我们分别对LN、IN和GN都按上式计算的话就会发现,bias对于IN来说也是没有意义的,但是对于LN和GN则有意义。
结论
当归一化在与通道垂直的方向上做(逐通道)时,就不应该添加bias。如果模型中使用BN和IN,那么都不应该加bias,而GN和LN则应该加bias。
reference
[1]. Yuxin Wu and Kaiming He. Group Normalization. In ECCV, 2018.
[2]. Sergey Ioffe and Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In ICML, 2015.
[3]. Lei Jimmy Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization. arXiv:1607.06450, 2016.
[4]. Dmitry Ulyanov, Andrea Vedaldi and Victor S. Lempitsky. Instance normalization: The missing ingredient for fast stylization. arXiv:1607.08022, 2016.