link: 1706.03762 (arxiv.org)
3. Methods
Transformer总体上沿用编码器-解码器架构,组件由自注意力和全连接层堆叠而成,核心架构如下图:
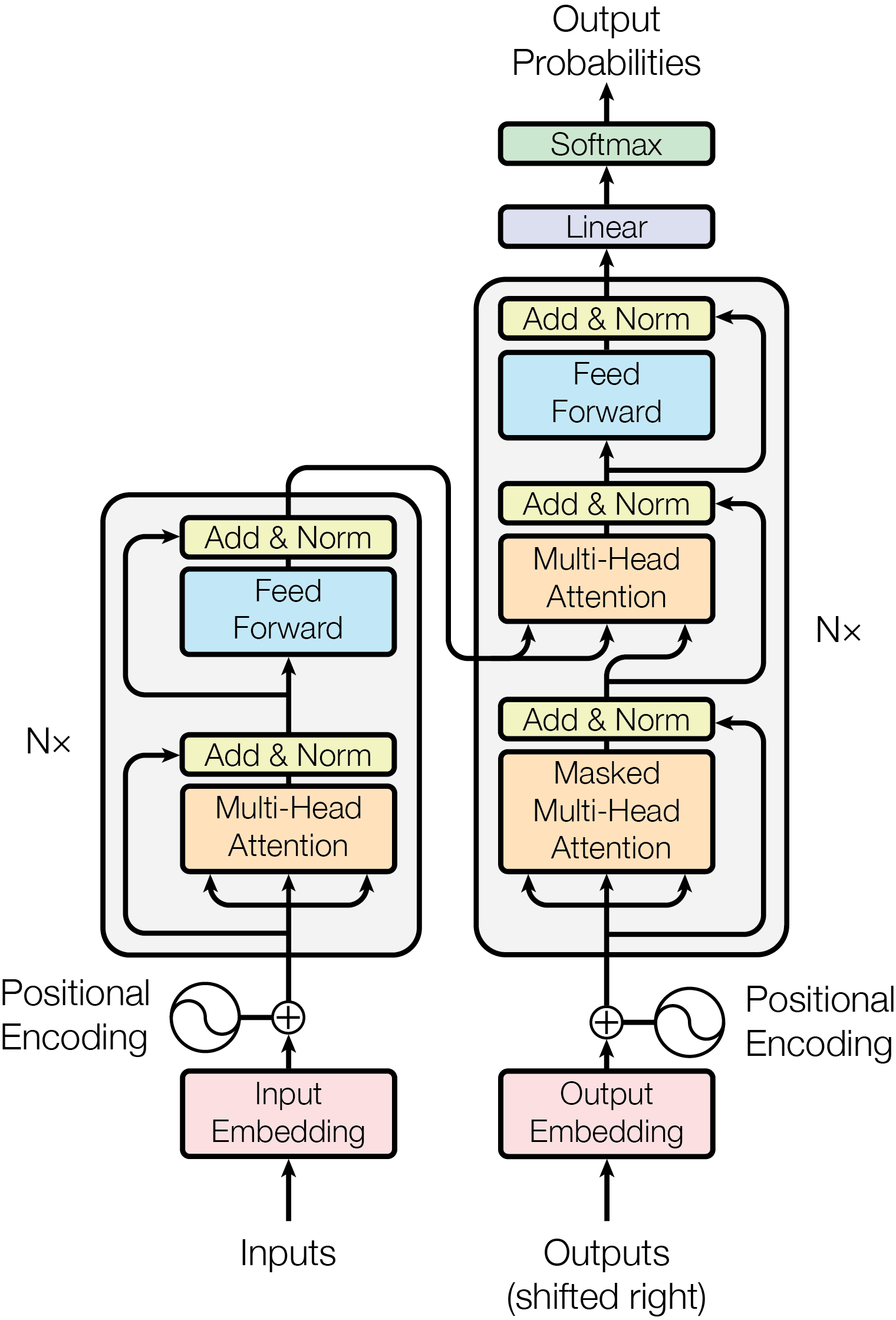
3.1 编码器-解码器堆叠架构
3.1.1 编码器
编码器由6个相同的网络块堆叠组成。每个网络块有两个子层,第一个子层是一个多头自注意力机制(multi-head
self-attention
mechanism),第二个子层是一个全连接层。两个子层都采用残差连接和LayerNorm。值得注意的是,所有的子层输入输出维度都是
为什么使用LayerNorm?通常使用BN,BN会将所有的样本一起归一化,如果样本长度变化大,那么计算出的均值和方差抖动较严重。
3.1.2 解码器
解码器同样由6个相同的网络块堆叠组成。每个网络块有三个子层,除了两个与编码器子层相同的层外,多了一个处理编码器输出的多头注意力层,即Masked Multi-Head Attention。这一层使得位置i的输出只能依赖于位置i之前的结果,这对于自然语言处理来说是个很自然的考虑。
3.2 注意力机制
Transformer中的注意力机制使用三个特征变量描述:查询(query, Q)、键(key, K)和值(value, V)。计算Q和K之间的相似度作为权重,将权重作用于V得到的加权和即为输出结果。
3.2.1 基本注意力单元
文章中将这种基本注意力单元称为“缩放的点乘注意力”(Scaled Dot-Product Attention),点明了这种注意力的两个重要计算:点乘、缩放。
假设输入的查询和键维度为
3.2.2 多头注意力
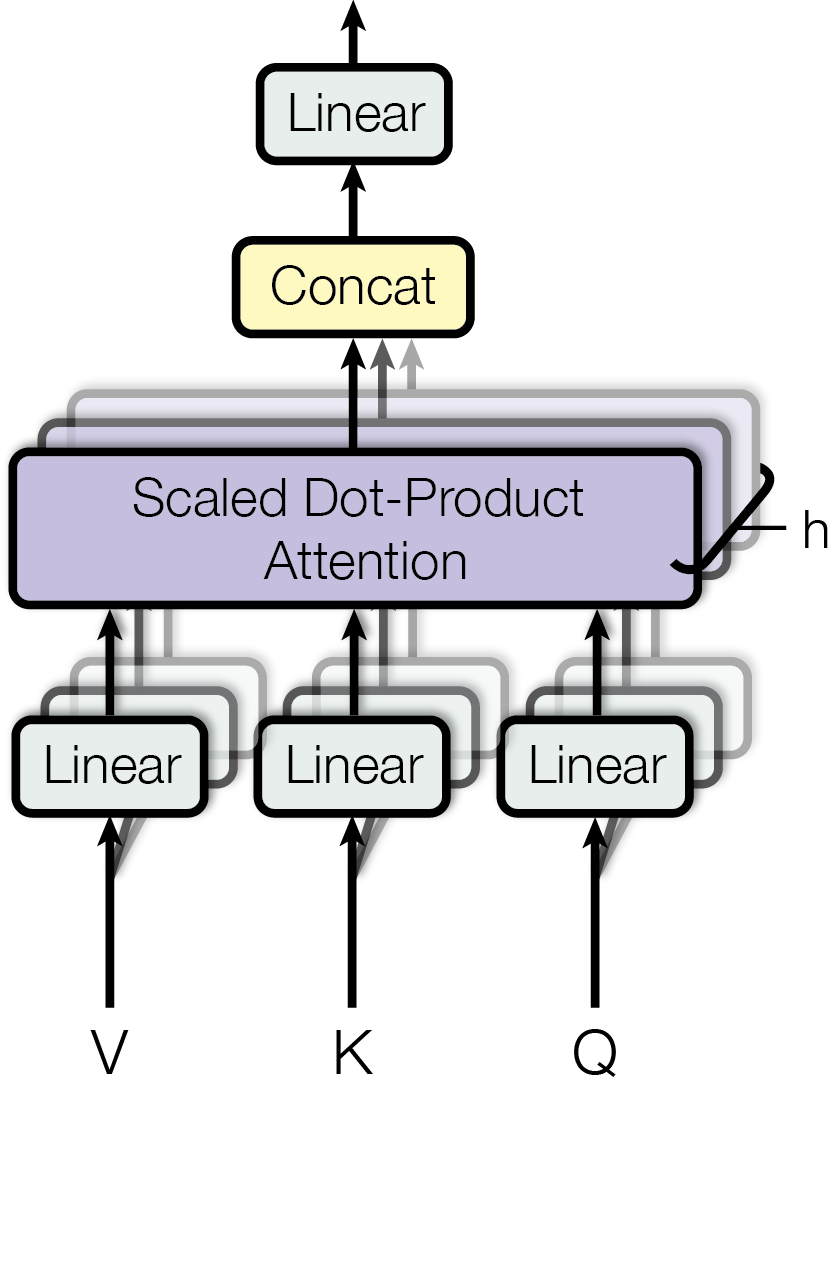
实际使用时并不是直接堆叠点乘注意力单元,而是将
多头注意力计算公式如下:
这这篇文章中,
3.2.3 Transformer中的注意力
Transformer中多头注意力有以下三种用法:
- 解码器中的
Multi-head Attention:Q来自于先前的解码器层;K和V来自于编码器的输出,这样Q与K和V来自于不同序列的注意力被称为cross -attention。每个位置都可以看到上一层的全部位置。 - 编码器中的
Multi-head Attention:Q、K和V相同,是上一个编码器层的输出,这样的层被称为自注意力层。每个位置都可以看到上一层的全部位置。 - 解码器中的
Masked Multi-Head Attention:同样是一个自注意力层,但是其中每个位置都不能看到上一层其后边位置的内容。
3.3 前馈网络
每个编码器、解码器块中除了有注意力子层还包含一个应用于每一个位置(position)的全连接前馈网络。这个网络由两个线性层和一个ReLU激活函数组成:
除了使用全连接网络,也可以使用核为1的卷积网络。
3.4 位置编码
Transformer中不使用RNN或CNN,为了维护输入序列顺序信息,对输入Embedding做位置编码,再将位置编码和Embedding相加起来。
4. 为什么要用自注意力?
这一节对自注意力层和RNN层、CNN层做一个量化的对比。存在一个任务,要把序列
| Layer Type | Complexity per Layer | Sequential Operations | Maximum Path Length |
|---|---|---|---|
| Self-Attention | 𝑂(1) | 𝑂(1) | |
| Recurrent | 𝑂(𝑛) | 𝑂(𝑛) | |
| Convolutional | 𝑂(1) | ||
| Self-Attention (restricted) | 𝑂(𝑟⋅𝑛⋅𝑑) | 𝑂(1) | 𝑂(𝑛/𝑟) |
自注意力可以直接看到全图的信息,即上下文路径长度复杂度为𝑂(1),其注意力机制避免了像RNN一样循环依赖于上一次结果,所以可以并行计算,复杂度为𝑂(1),计算复杂度根据注意力的推导公式也可以推出是