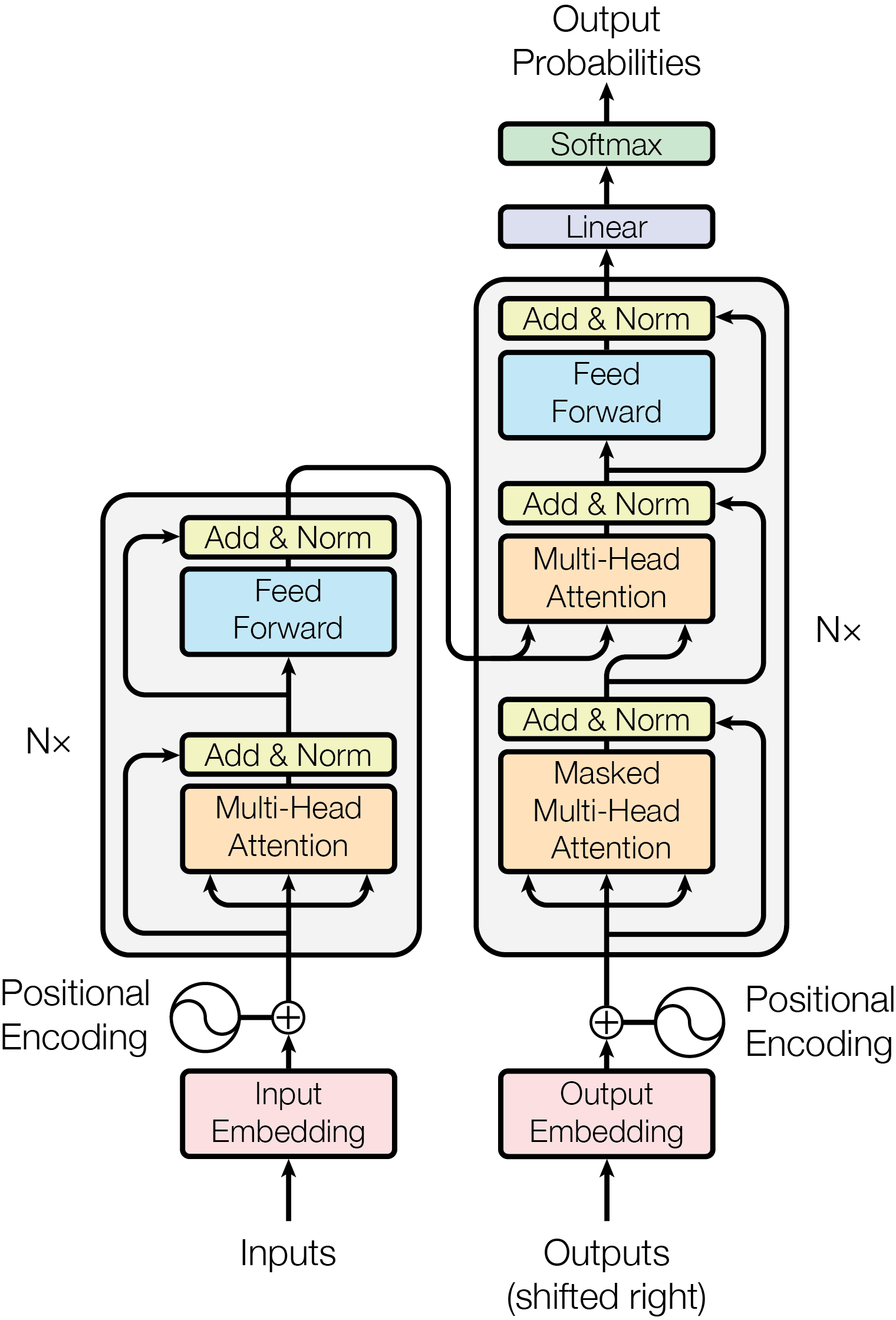
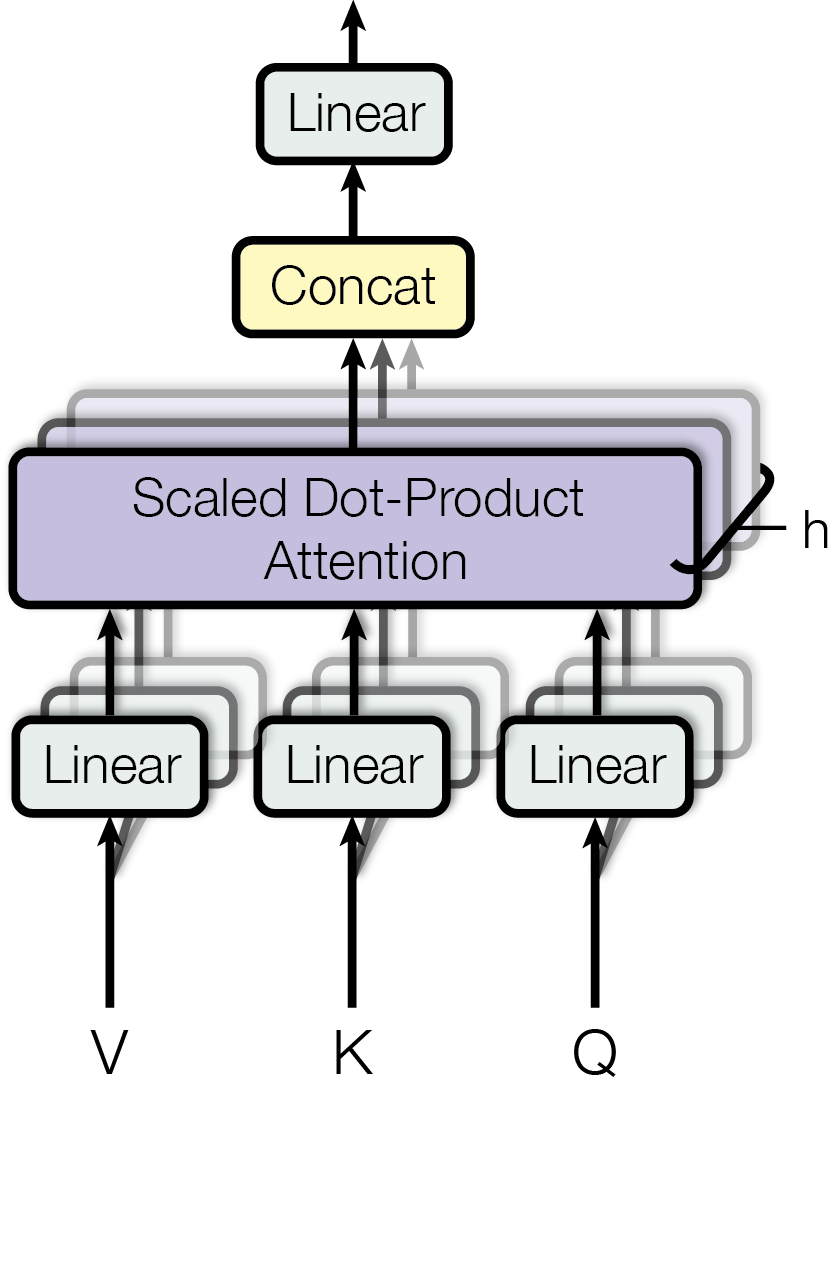
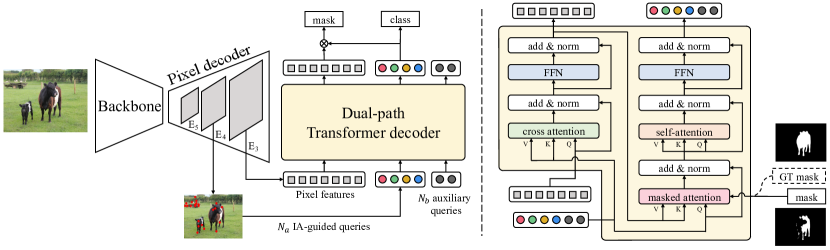
[1].
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexan der Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. In CVPR, 2022.
[2].
Tianheng Cheng, Xinggang Wang, Shaoyu Chen, Wenqiang Zhang, Qian Zhang, Chang Huang, Zhaoxiang Zhang, and Wenyu Liu. Sparse instance activation for real-time instance segmentation. In CVPR, 2022.
[3].
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. In ICLR, 2021.
[4].
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to end object detection with transformers. In ECCV, 2020.
Welcome to Hexo! This is your very
first post. Check documentation for
more info. If you get any problems when using Hexo, you can find the
answer in troubleshooting or
you can ask me on GitHub.
lock = FileLock(lockfile) lock.acquire() try: print("acquire the lock!") # do something to the file... finally: lock.release() print("release the lock!")